Why?
This is a let’s turn my notes into a post writing. I like to pick up NetWare-related reverse engineering endeavors every now and then, and most of these involve having a NetWare 3.12 server available somewhere. In current day and age, that means a VM or emulator. I like to use QEMU, so I’ll be using that.
Prerequisites
- NetWare 3.12 ISO. Available at https://archive.org/details/novell-netware-3.12.
- NetWare 3.12 license diskettes. Available at https://archive.org/details/nw-3.12-license-disks.
- MS-DOS 6.22. Available at https://archive.org/details/MS_DOS_6.22_MICROSOFT.
- MS-DOS CD-ROM driver. Available at https://archive.org/details/OAKCDROM.
- NetWare 3.12 patch. Available at https://ftp.zx.net.nz/pub/archive/novell/servers/3.12/312PTD.EXE.
- ODI patches. You wil need https://ftp.zx.net.nz/pub/archive/novell/servers/3.12/odi33g.exe.
- LAN drivers. You will need https://ftp.zx.net.nz/pub/archive/novell/servers/3.2/extra/LANDRV.EXE.
- AMD PC-NET driver + patches. Available at https://archive.org/details/novell-netware-3.12_amdpcnet.
Step 1: Initial MS-DOS installation
First, we need to create a disk image to contain our NetWare installation. I’ve chosen 500MB as that contains plenty of space, and making it (much) larger will cause troubles due to Cylinders/Heads/Sectors limitations in the ISADISK.DSK driver. I’m using a raw image as it’s easy to inspect/mount from a Linux host, but this isn’t necessary.
> qemu-img create -f raw novell312.img 500M
> qemu-system-i386 -hda novell312.img -cdrom novell-netware-3.12.iso -fda "Disk 1.img" -boot a -m 8 -monitor stdioExit setup using F3, run fdisk. Create a 32MB active partition to use for MS-DOS (create partition (1), primary (1), answer N, 32. set active (2), 1, escape).
After rebooting, continue installation of MS-DOS. You can change the floppy disks by issuing the following command in the (qemu) monitor window:
(qemu) change floppy0 "Disk 2.img"
(qemu) change floppy0 "Disk 3.img"After installation completes, use eject floppy0 to remove the virtual floppy.
Step 2: CD-ROM drivers
Use the qemu monitor console to insert the CD-ROM floppy (change floppy0 OAKCDROM.img).
copy a:\oakcdrom.sys c:\edit c:\config.sys– addDEVICE=C:\OAKCDROM.SYS /D:MSCD001)- Reboot (In the QEMU window, use the menu bar and select Machine -> Reset)
Step 3: NetWare installation
You’ll need to choose which NetWare license diskette you want to use. I will be using NW312_SYSTEM_1__05_user_01.vfd – use the qemu monitor console to insert this floppy (change floppy0 ...)
mscdex /d:mscd001d:cd netware.312\englishinstall.bat- Install a new NetWare v3.12
- Retain current disk partitions
- Server name:
NW312 - Accept the randomized IPX network
- Continue
- Accept locale settings (F10)
- DOS Filename Format
- No (no special startup commands)
- Yes (load server.exe from autoexec.bat)
Step 4: NetWare configuration
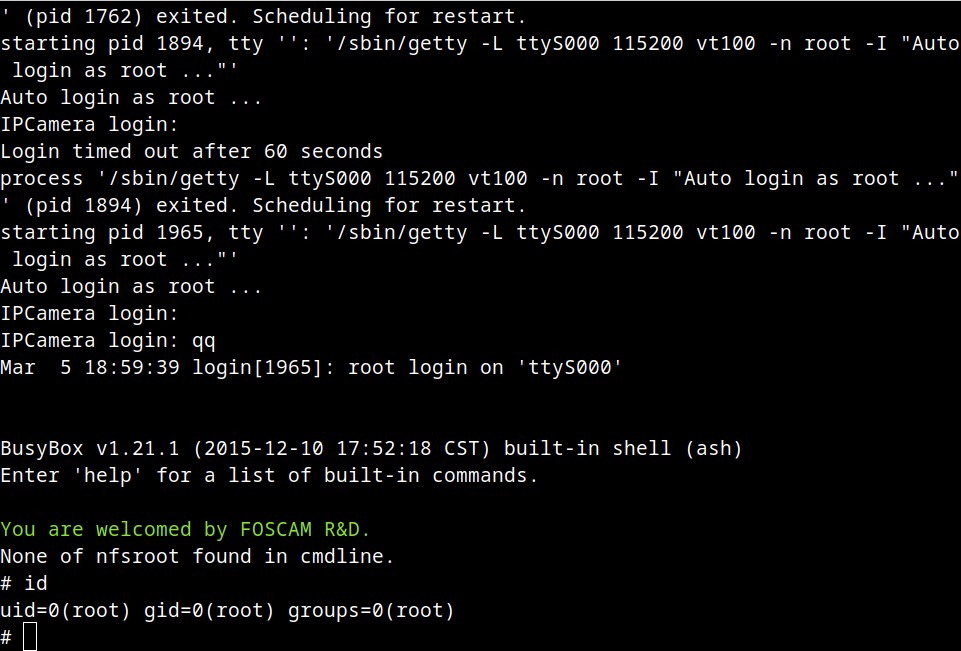
You should now be greeted with a NW312: prompt.
load isadisk- Accept the defaults for I/O and interrupt (1F0, E)
load install- Disk Options -> Partition Tables -> Create NetWare Partition. Escape to accept, Yes (Create Partition)
- Return to main menu (escape, escape)
- Volume Options -> <INSERT> -> Escape -> Yes.
- Enter to select the SYS volume, use down arrow key to go to status -> Enter -> Mount Volume
- Return to main menu (escape, escape)
- System -> Copy System And Public Files
- F6, D:\NETWARE.312\ENGLISH
- (This will take a long time)
- Escape to close the message
- Create AUTOEXEC.NCF File
- Escape, Yes (Save)
- Create STARTUP.NCF File
- Escape, Yes (Save)
Step 5: NetWare Patches / drivers
It is a hassle getting files onto the NetWare VM. We’ll be creating a 1.44MB floppy disk image and copy the files from Linux to it. Then we will extract the archives to the local FAT drive as applicable.
First of all, open the LANDRV.EXE file using an archive manager (MATE’s Engrampa opens it just fine) and extract AMD/LAN32DRV/PCNTNW.LAN to /tmp. Then:
> dd if=/dev/zero of=tmp.img bs=512 count=2880
> mformat -i tmp.img ::/
> mcopy -i tmp.img odi33g.exe ::/
> mcopy -i tmp.img 312ptd.exe ::/
> mcopy -i tmp.img nw-idle4.nlm ::/
> mcopy -i /tmp/PCNTNW.LAN 312ptd.exe ::/Use the Qemu monitor console change floppy0 tmp.img to insert the floppy.
Within NetWare, use down to stop the server and exit to return to DOS. We proceed to copy the LAN driver and extract the patches:
C:\SERVER.312> COPY A:\*.LAN .
C:\SERVER.312> MKDIR \ODI
C:\SERVER.312> CD \ODI
C:\ODI> A:\ODI33G
[ enter Y to extract the contents ]
C:\ODI> MKDIR \312PTD
C:\ODI> CD \312PTD
C:\312PTD> A:\312PTD
[ enter Y to extract the contents ]
C:\312PTD> CD \SERVER.312
C:\SERVER.312> SERVER
NW312: load c:\312ptd\312ptd\patch312.nlm
[ select PATCH OS ]
Directory is C:\312PTD\312PTD
NW312: load install
[ Product Options ]
C:\ODI\SERVER
Step 6: LAN driver
We need to instruct the server to load the AMD PC-NET LAN driver and connect IPX services to it. To do so, we run INSTALL to edit the AUTOEXEC.NCF file:
NW312: load install
[ System Options ]
[ Edit AUTOEXEC.NCF File -- and add the following lines ]
load c:pcntnw frame=Ethernet_II
bind ipx to pcntnw net=1234Step 7: Linux network configuration
The best network adapter to use is AMD-NET LAN. Create a script named qemu-ifup, insert the following contents and make sure it is executable (chmod 755):
#!/bin/sh
ip link set $1 promisc on
brctl addif br0 $1
ip link set $1 upThis will add the network device to a bridge, which means it will be connected to your LAN. To create the bridge, issue the following commands (replace eno1 by your network interface,and a.b.c.d/xx and a.b.c.e by your IP address and router)
# Create bridge and assign the network interface to it
> brctl addbr br0
> ip link set br0 up
> brctl addif br0 eno1
# Remove IPv4 address from eno1
> ip addr del a.b.c.d/xx dev eno1
# Assign IPv4 address to bridge
> ip addr add a.b.c.d/xx dev br0
# Set default router
> ip route add default via a.b.c.eCreate a script (I use nw312.sh) to launch the NetWare 3.12 server:
qemu-system-i386 -hda novell312.img -m 8 -device pcnet,netdev=lan,mac=36:1b:67:80:3c:69 -netdev tap,id=lan,ifname=tap1,script=qemu-ifup $@I’ve picked a random MAC address with help from https://random.org/bytes to avoid interfering with qemu’s default MAC address.
Caveats
- I’m not convinced all patches are properly installed (even though the instructions say they are) because the PCNTNW.LAN driver complains about protected mode BIOS accesses, which is what one of the patches was supposed to fix.
- The Y2K patches are not installed, so my server believes it is 1925 as of writing. I don’t consider this an issue.
- Some guides recommend to install
nw4-idle.nlm, yet this feels it degrades performances (the server seems to respond slower).